We covered the motivation behind SRE in the first blogpost of this series, followed by Principles and Practices. Lets complete the foundation with Google’s guidance on how to get SREs working together in a team and working as teams. To ensure SRE approach sticks without the team slipping back to old ways, the new ways of working covered in this blogpost should be incorporated in a structured manner along with the team and the management committing to adhere to them at all costs.
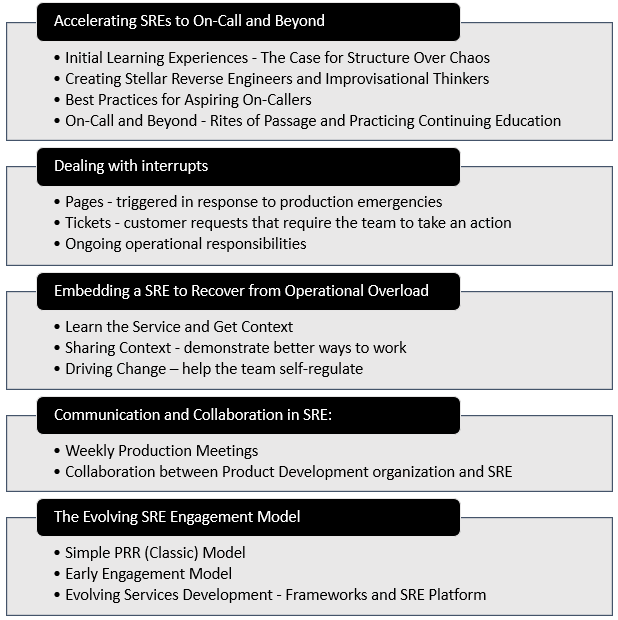
Accelerating SREs to On-Call and Beyond: Educating new SREs on concepts and practices up front will shape them into better engineers and make their skills more robust.
- Initial Learning Experiences – The Case for Structure Over Chaos: SRE must handle a mix of proactive (engineering) and reactive (on-call) work while traditional Operations teams are predominantly reactive. To position the team for success with proactive work, structured knowledge build-up of the system is essential. Some techniques for getting there:
- Learning Paths That Are Cumulative and Orderly – Show the new SRE team an orderly path that will infuse confidence that there is a plan to mastery of the system through a combination of education, exposure and experience.
- Targeted Project Work, Not Menial Work – Make the initial weeks effective by giving the engineers project work that can reinforce their learning.
- Creating Stellar Reverse Engineers and Improvisational Thinkers: SREs will continue to encounter systems with design patterns that they have not seen before. They need strong reverse engineering skills along with ability to think statistically and improvise fully to untangle without avoid getting stuck.
- Best Practices for Aspiring On-Callers: For engineers who typically prefer creating new tech solutions, being on-call to troubleshoot production issues can be made interesting with the following practices:
- A Hunger for Failure: Reading and Sharing Postmortems
- Disaster Role Playing (regular team exercises for new joiners to enact responding to pages)
- Break Real Things, Fix Real Things (by simulating volumes or issues in non-critical lower environments)
- Documentation as Apprenticeship (by overhauling outdated knowledge base)
- Shadow On-Call Early and Often
- On-Call and Beyond – Rites of Passage and Practicing Continuing Education: Once the engineer has demonstrated ability to handle issues independently, it is time to be formally added to on-call rota and celebrate this milestone as a team. It is important to setup a regular learning series that helps the entire team stay in touch with changes.
Dealing with interrupts: Once the SRE team is in-charge of handling operations, “Managing Operational Load” is the next topic to focus on. Operational Load is the work that must be done to maintain the system in a functional state, and this will interrupt the SRE team working on any other planned project work. So, the objective is to handle such interruptions without distracting the engineers from their cognitive flow state. The interrupts fall into three general categories:
- Pages concern production alerts and are triggered in response to production emergencies. They are commonly handled by a primary on-call engineer, who is focused solely on on-call work. A person should never be expected to be on-call and also make progress on projects or anything else with a high context switching cost. A secondary on-call engineer provides back-up in case of contingencies.
- Tickets concern customer requests that require the team to take an action. The primary or secondary on-call engineer can work on tickets when there are no pages to handle. Depending on the nature and priority of tickets, a dedicated person might also be assigned to work on tickets.
- Ongoing operational responsibilities include activities like team-owned code or flag rollouts, or responses to ad-hoc, time-sensitive questions from customers. An approach similar to handling tickets can be adopted.
Embedding a SRE to Recover from Operational Overload: A burdensome amount of ops work for a prolonged period will be dangerous because the SRE team might burn out or be unable to make progress on project work. One way to relieve this burden is to temporarily transfer a SRE into the overloaded team. Google’s guidance to the SRE who will be embedded on a team:
- Phase 1: Learn the Service and Get Context – Remind the team that more tickets should not require more SREs and emphasize on healthy work habits that reduce the time spent on tickets. Some of the healthy habits are focusing on non-linear scaling of services, identifying sources of inordinate amount of stress, and identifying emergencies waiting to happen.
- Phase 2: Sharing Context – After identifying pain points, suggest improvements and demonstrate better ways to work. Some examples are writing a good postmortem for the team or identifying root cause for frequent issues and suggesting solutions.
- Phase 3: Driving Change – Nudge the team with ideas based on SRE principles and help them self-regulate. This can be done by helping the team fix any basic issues (like defining SLO), coaching team members to address issues in a permanent way or asking leading questions.
Communication and Collaboration in SRE: There is tremendous diversity in SRE teams as it includes people with various skills such as systems engineering, software engineering, project management, etc. Also, given the nature of responsibilities handled by SRE, team members tend to be more distributed across geographical regions and time zones when compared to product development. Considering these aspects, communication and collaboration among SRE teams and across other teams should be designed to address the joint concerns of production and the product in an atmosphere of mutual respect. There should be forums (like weekly Production Meetings) for the SRE team to articulate the state of the system they support and highlight improvement opportunities to Product Development.
The Evolving SRE Engagement Model: The focus so far has been on onboarding SRE support for a product or service that is already in production. While this “classic” engagement model is commonly a good starting point, there are two other models that are better at embedding SRE principles and practices earlier during development lifecycle. Let’s looks at all the three models, starting with the classic one.
- Simple PRR (Classic) Model: When SRE receives a request for taking over production management, SRE gauges both the importance of the product and the availability of SRE teams. The SRE and development teams then agree on staffing levels to facilitate this support followed by a Production Readiness Review (PPR). Once the gaps and improvements identified from the review are addressed, SRE team assumes its production responsibilities.
- Early Engagement Model: SRE participates in Design and later phases, eventually taking over the service any time during or after the build phase.
- Evolving Services Development – Frameworks and SRE Platform: As the industry moves towards microservices architecture, the number of requests for SRE support and the cardinality of services to support will increase. To effectively address the increased demand, all microservices should adopt structured frameworks for production services. These frameworks include codified SRE best practices that are “production ready” by design and reusable solutions to mitigate scalability and reliability issues. A production platform built on top of such frameworks with stronger conventions reduces operational overhead.
These five ways to work should help establish and reinforce SRE teams in an organization. And with this, we come to the end of SRE overview series. I strongly recommend reading Google’s book to get a comprehensive understanding of SRE. As the industry moves further towards microservices and cloud, traditional support model that is predominantly based on manual operations will not be scalable and sustainable. The sooner organizations embark on pivoting towards an engineering-oriented support model with necessary investments in technology and people, the better for products and services they provide.