After covering the motivation behind SRE along with the responsibilities and principles in previous blogposts, this one will focus on “how” to get there by leveraging SRE practices used by Google. The book explains 18 practices and I strongly recommend reading the book to thoroughly understand them. I have provided a brief summary of the most common and relevant practices here.
The book has characterized the health of the service similar to Maslow’s hierarchy of human needs, with basic needs at the bottom (starting with Monitoring) and goes up all the way to taking proactive control of the product ‘s future rather than reactively fighting fires. All the practices fall under one of these categories.
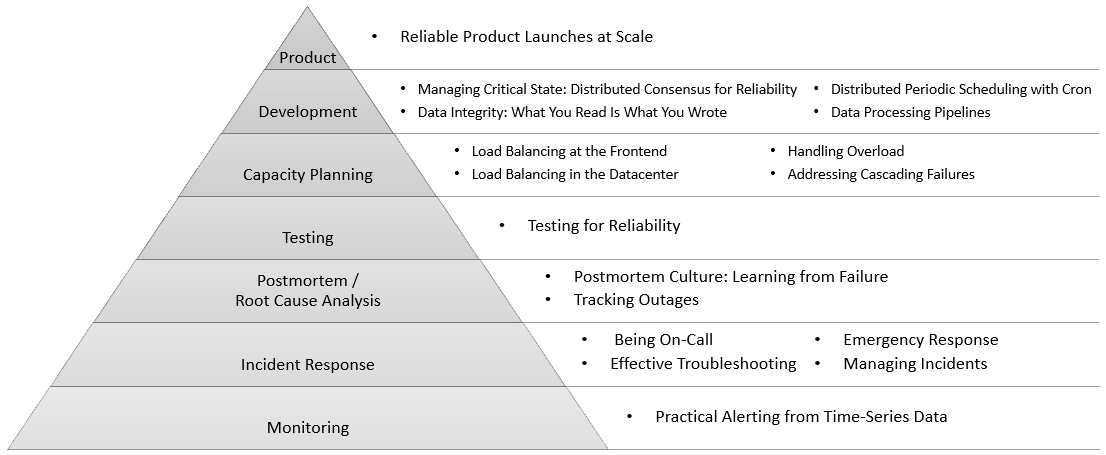
Monitoring: Any software service cannot sustain in the long term if customers usually come to know of problems before the service provider. To avoid this situation of flying blind, monitoring has always been an essential part of supporting a service. Many organizations have L1 Service Desk teams that either manually perform runbook based checks or visually monitor dashboards (ITRS, App Dynamics, etc.) looking for any service turning “red”. Both these approaches involve manual activity, which make monitoring less effective and inefficient. Google being a tech savvy organization, always had automated monitoring through custom scripts that check responses and alert.
- Practical Alerting from Time-Series Data: As Google’s monitoring systems evolved using SRE, they transformed to a new paradigm that made the collection of time-series a first-class role of the monitoring system, and replaced those check scripts with a rich language for manipulating time-series into charts and alerts. Open source tools like Prometheus, Riemann, Heka and Bosun allow any organization to adopt this approach. For organizations still relying heavily on L1 Service Desks, a good starting point will be to use a combination of white-box and black-box monitoring along with a production health dashboard and optimum alerting to eliminate the need for manual operations that only scales linearly.
Incident Response: Incidents that disrupt a software service dependent on numerous interconnected components is inevitable. SRE approaches these incidents as an opportunity to learn and remain in touch with how distributed computing systems actually work. While Incident Response and Incident Management are used interchangeably at some places, I consider Incident Response that includes technical analysis and recovery to be the primary responsibility of SRE team, whereas Incident Management deals with communication with stakeholders and pulling the who response together. Google has also called out Managing Incidents as one of the four practices under Incident Response:
- Being On-Call is a critical duty for SRE team to keep their services reliable and available. At the same time, balanced on-call is essential to foster a sustainable and manageable work environment for the SRE team. The balance should ensure there is no operational overload or underload. Operational overload will make it difficult for the SRE team to spend at least 50% of their time on engineering activities leading to technology debt and inefficient manual workarounds creeping into support process. Operational underload can result in SREs going out of touch with production creating knowledge gaps that can be disastrous when an incident occurs. On-call approach should enable engineering work as the primary means to scale production responsibilities and maintain high reliability and availability despite the increasing complexity and number of systems and services for which SREs are responsible.
- Effective Troubleshooting: Troubleshooting is a skill similar to riding a bike or driving a stick-shift car, something that becomes easy once you internalize the process and program your memory to subconsciously take necessary action. In addition to acquiring generic troubleshooting skill, solid knowledge of the system is essential for a SRE to be effective during incidents. Building observability into each component from the ground up and designing systems with well-understood interfaces between components will make troubleshooting easier. Adopting a systematic approach to troubleshooting (like Triage -> Examine -> Diagnose -> Test / Treat cycle) instead of relying on luck or experience will yield good results and better experience for all stakeholders.
- Emergency Response: “Don’t panic” is the mantra to remember during system failures to be able to recover effectively. And to be able to act without panic, training to handle such situations is absolutely essential. Test-Induced emergency helps SRE proactively prepare for such eventualities, make changes to fix the underlying problems and also identify other weaknesses before they became outages. In real life, emergencies are usually change-induced or process induced and SREs learn from all outages. They also document the failure modes for other teams to learn how to better troubleshoot and fortify their systems against similar outages.
- Managing Incidents: Most organizations already have an ITIL based Incident management process in place. SRE team strengthens this process by focusing on reducing mean time to recovery and providing staff a less stressful way to work on emergent problems. The features that can help achieve this are recursive separation of responsibilities, a recognized command post, live incident state document and clear handoff.
Postmortem and Root Cause Analysis: SRE philosophy aims to manually solve only new and exciting problems in production unlike some of the traditional operations-focused environments that end up fixing the same issue over and over.
- Postmortem Culture of Learning from Failure has primary goals of ensuring that the incident is documented, all contributing root causes are well understood and effective preventive actions are put in place to reduce the likelihood and impact of recurrence. As the postmortem process involves inherent cost in terms of time and effort, well defined triggers like incident severity is used to ensure root cause analysis is done for appropriate events. Blameless postmortems are a tenet of SRE culture.
Testing: The previous practices help handle problems when they arise but preventing such problems from occurring in the first place should be the norm.
- Testing for Reliability is the practice that helps adapting classical software testing techniques to systems at scale and improve reliability. Traditional tests during software development stage like unit testing, integration testing and system testing (smoke, performance, regression, etc.) help ensure correct behavior of the system before it is deployed into production. Production tests like stress / canary / configuration tests are similar to black-box monitoring that help proactively identify problems before users encounter them and also help staggered rollouts that limits any impacts in production.
Capacity Planning: Modern distributed systems built using component architecture are designed to scale on demand and rely heavily on diligent capacity planning to achieve it. The following four practices are key:
- Load balancing at the Frontend: DNS is still the simplest and most effective way to balance load before the user’s connection even starts but has limitations. So, the initial level of DNS load balancing should be followed by a level that takes advantage of virtual IP addresses.
- Load balancing in the data center: Once the request arrives at the data center, the next step is to identify the right algorithms for distributing work within a given datacenter for a stream of queries. Load balancing policies can be very simple and not take into account any information about the state of the backends (e.g., Round Robin) or can act with more information about the backends (e.g., Least-Loaded Round Robin or Weighted Round Robin).
- Handling Overload: Load balancing policies are expected to prevent overload but there are times when the best plans fail. In addition to data center load balancing, per-customer limits and client-side throttling will help spread load over tasks in a datacenter relatively evenly. Despite all precautions, when backend is overloaded, it need not turn down and stop accepting all traffic. Instead, it can continue accepting as much traffic as possible, but to only accept that load as capacity frees up.
- Addressing cascading failures: A cascading failure is one that grows over time as a result of positive feedback. It can occur when a portion of an overall system fails, increasing the probability that other portions of the system fail. Increasing resources, restarting servers, dropping traffic, eliminating non-critical load, eliminating bad traffic are some of the immediate steps that can address cascading failures.
Development: All the practices covered so far deal with handling reliability after software development is complete. Google recommends significant large-scale system design and software engineering work within the organization to enable SRE through following practices:
- Managing Critical State – Distributed Consensus for Reliability: CAP Theorem provides the guiding principle to determine the properties that are most critical. When dealing with distributed software systems, we are interested in asynchronous distributed consensus, which applies to environments with potentially unbounded delays in message passing. Distributed consensus algorithms allow a set of nodes to agree on a value once but don’t map well to real design tasks. Distributed consensus adds higher-level system components such as datastores, configuration stores, queues, locking, and leader election services to provide the practical system functionality that distributed consensus algorithms don’t address. Using higher-level components reduces complexity for system designers. It also allows underlying distributed consensus algorithms to be changed if necessary in response to changes in the environment in which the system runs or changes in nonfunctional requirements.
- Distributed Periodic Scheduling with Cron, Data Processing Pipelines and ensuring Data Integrity: What You Read Is What You Wrote are other practices during Development.
Product is at the top of the pyramid for any organization. Organizations will benefit by practicing Reliable Product Launches at Scale using Launch Coordination Engineering role to setup a solid launch process with launch checklist.
These practices shared by Google provide a comprehensive framework to adopt across software development lifecycle to improve reliability, resilience and stability of systems.