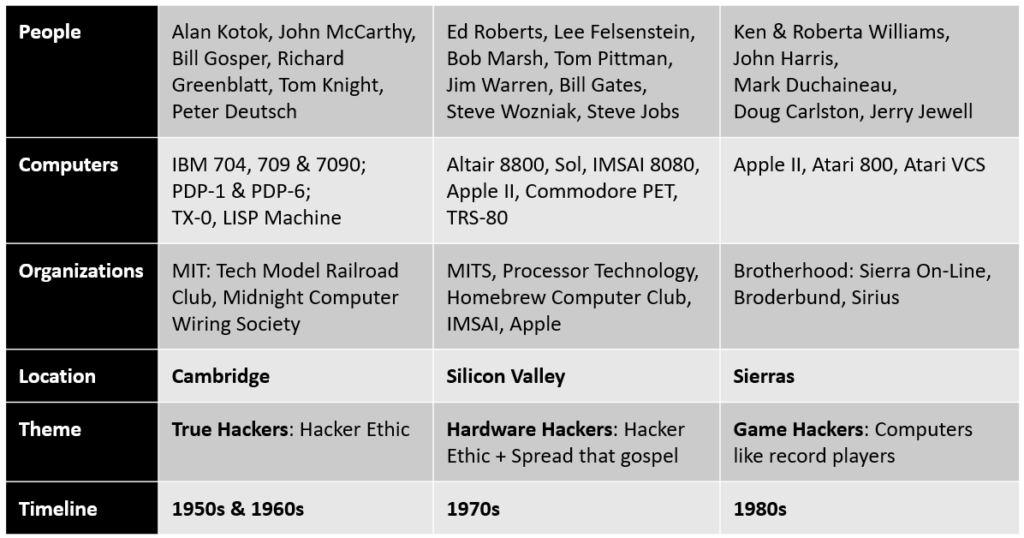
We are taught from childhood that “no pain, no gain”, emphasizing the importance of spending time and effort to achieve results. Once we grow up, we encounter self-help books that teach us to pivot towards working “smart”, not just “hard” and present their own theories and practices to make their point. All of them are based on the author’s personal experiences and beliefs, and we can benefit by learning from them and customizing for ourselves. One such book that stuck a chord with me is “Deep Work” by Cal Newport. Just as I finished the chapter on Rule #1 – Work Deeply, I was able to connect my learnings to a challenge my son wanted help with and immediately wrote this blog post with my thoughts.
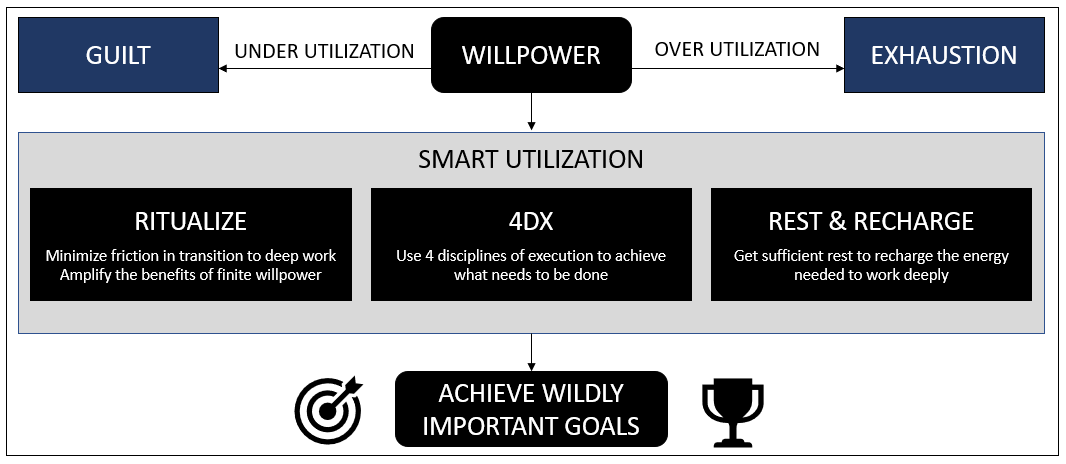
Let me start with references from the book, followed by my inferences that will explain the picture above.
- Roy Baumeister on willpower: You have a finite amount of willpower that becomes depleted as you use it.
- Ritualize: To make the most out of your deep work sessions, build rituals of the same level of strictness and idiosyncrasy. These rituals will minimize the friction in transition to depth, allowing us to go deep more easily and stay in that state longer.
- 4DX: The 4 disciplines of execution (abbreviated 4DX) is based on the fundamental premise that execution is more difficult than strategizing. It helps address the gap between what needs to be done (strategy) and how to do it (execution):
- Discipline #1: Focus on the Wildly Important – Ironically, the more you try to do by pushing too hard, the less you accomplish. So, execution should be aimed at a small number of “wildly important goals”.
- Discipline #2: Act on the Lead Measures – There are two types of measures for success – lag measures and lead measures. Lag measures describe the thing you are ultimately trying to improve while lead measures focus on the new behaviors that will drive success on the lag measures. The problem with lag measures is that they come too late to change your behavior. So, start with acting on lead measures.
- Discipline #3: Keep a Compelling Scoreboard – An always visible scoreboard creates a sense of competition that drives us to focus on these measures, even when other demands vie for our attention. It also provides a reinforcing source of motivation. Finally, it allows us to recalibrate expectations as required to achieve what is wildly important (like an agile burndown chart will help the team recalibrate efforts required to meet sprint goals).
- Discipline #4: Create a Cadence of Accountability – A periodic review of scoreboard helps us to review progress towards lag measures and pivot as required in case the progress does not really converge towards producing the ultimate results expected.
- Be Lazy: Tim Kreider in his “The Busy Trap” blog says – “I am not busy. I am the laziest ambitious person I know” and goes on to explain “Idleness is not just a vacation, an indulgence or a vice; it is as indispensable to the brain as vitamin D is to the body, and deprived of it we suffer a mental affliction as disfiguring as rickets. The space and quiet that idleness provides is a necessary condition for standing back from life and seeing it whole, for making unexpected connections and waiting for the wild summer lightning strikes of inspiration — it is, paradoxically, necessary to getting any work done“. So, periodic shutdown from work will enhance our ability to produce valuable output due to the following reasons:
- Reason #1: Downtime aids insight – Unconscious Thought Theory (UTT) posits that the unconscious mind is capable of performing tasks outside of one’s awareness, and that unconscious thought (UT) is better at solving complex tasks. The implication of this line of research is that providing your conscious brain time to rest enables your unconscious mind to take a shift sorting through your most complex professional challenges.
- Reason #2: Downtime helps recharge the energy needed to work deeply – Attention Restoration Theory (ART) asserts that people can concentrate better after spending time in nature, or even looking at scenes of nature. The core mechanism of this theory is the idea that you can restore your ability to direct your attention if you give this activity a rest.
- Reason #3: The work that regular downtime replaces is usually not that important – Working in information technology field for US multinationals from India means ones evening is core work time, attending meetings and discussions during the limited time zone “overlap” available. So, I replaced “evening downtime” with “regular downtime”, which for me is typically a few hours every morning when I go for my morning run and spend time with family. The point is that your capacity for deep work in a given day is limited and by setting aside some time for yourself to relax and reenergize, you are missing out on much of importance.
Putting it all together: Going back to my son’s challenge, he got an unexpected one week holiday as his school had to reschedule classes due to second covid-19 wave. He was initially happy with this change as he could spend time as he wished (usually video games) for an extra week but the willpower he had originally corralled to excel academically had gone unutilized resulting in his initial euphoria eventually turning into guilt.
As humans, we are usually tempted to engage in shallow activities that are easily enjoyable (like playing video games or watching our favorite TV show) instead of deep work (like studying or writing this blog). But we are also ambitious and aspirational with a need for achievement to make our life purposeful. Willpower helps us handle this conflict by motivating us to engage in deep work required for purposeful activities that are usually difficult. But our willpower is finite that depletes with use and needs to be recharged for sustenance. Overutilizing willpower will lead to exhaustion, underutilizing it will lead to guilt and smartly utilizing will produce great results for our wildly important goals. Smartly utilizing our willpower means:
- Using rituals to minimize the friction in transition to deep work and amplifying the benefits of finite willpower
- Using the 4 disciplines of execution to measure and progress towards our vision and goals
- Provide ourselves sufficient rest to recharge the energy needed to work deeply
With years of trial and error, I was already practicing some of these disciplines and this book provides additional structure that should make me more effective!